Deep Dive into open-appsec Machine Learning Technology
- Fortune Adekogbe
- Feb 6, 2023
- 8 min read
Updated: Feb 11, 2023
Introduction
open-appsec is an open-source web application firewall (WAF) that protects your web apps and APIs. It uses a machine learning (ML) engine to continuously analyze the HTTP/S requests made by users as they interact with your web application or API.
ML is a subset of artificial intelligence, and it describes a system where software can learn based on data inputs, different learning methods, and different decision algorithms. There are multiple learning methods that you can apply when creating your ML models, like supervised or reinforcement learning.
Depending on the method of learning and the algorithm you choose, your model can ultimately produce predictive or prescriptive outputs. In short, the model will either predict what will happen or suggest an action to take based on the given input and historical data contained in the model.
open-appsec uses these ML principles to create a powerful engine, powered by two different ML models, to analyze and classify every connection request sent to your web server.
In this article, you'll learn how open-appsec's ML model works. You'll also learn how you can implement it and set it up to achieve a more secure web app or API today.
open-appsec Implementation
open-appsec's implementation of a context-based ML model is a patented three-step approach:

The first step involves decoding whatever data is received over the network. Because it's possible for various components of the network to communicate with different rules (protocols), open-appsec uses parsers to handle common protocols, and it also analyses various aspects of the HTTP request.
Second, open-appsec runs the extracted data through a pre-trained ML model that effectively identifies attack indicators and reports a rating of the received data depending on how potentially harmful it is. Typically, a combination of indicators is evaluated, and an initial, cumulative confidence score is obtained for the payload.
Last, if there was some initial confidence achieved in the previous step that there might be indeed an attack, then a more thorough confidence score is calculated by performing advanced analytics based on criteria such as the request source's reputation, an understanding of the application's behavior and usage patterns, a measure of false detection, and an optional module that allows administrators to provide their input.
In order for the performance of open-appsec's contextual ML engine to improve, the model needs to be able to distinguish among the sources of incoming requests. When the model can comfortably identify these sources, you can further configure it by including trusted sources. This provides even more context on what a good source is and helps the model learn faster and perform better.
When you initially configure your application to be secured by open-appsec, the model can be in one of two modes: Detect-learn or Prevent.
There are a number of learning levels reached over time that will range from kindergarten to PhD. With proper configuration and enough application traffic, it's possible for your model to have learned enough to move into the prevention mode in as few as two to three days. As the model learns to protect you, it also brings up certain events for review, giving you an access point to the learning process. Though this is optional, it can help get your model to a higher learning level faster.
How open-appsec's ML Technology Works
open-appsec enables you to implement preemptive threat protection in your application and helps protect against the OWASP Top Ten attacks as well as newly identified attacking patterns, including a Log4j vulnerability exploit.
With open-appsec, you don't have to constantly update your signatures when a new threat is identified, and you don't risk compromising your application in the time between when a threat is identified and when an update is pushed, as the vulnerability window challenge is remediated effectively.
In addition, unlike other web application firewalls, like Azure WAF and Amazon Web Services (AWS) WAF, open-appsec's ML solution doesn't require you to maintain an ever-increasing list of threat signatures or continuously update the range of exceptions that need to be handled. Later, you'll take a more detailed look at the various features and components that make open-appsec a superior WAF solution.
Contextual ML
As previously stated, the contextual ML technology used by open-appsec employs a three-phase strategy to safeguard your online web applications and APIs. This method enables it to detect and prevent assaults with minimal threat misclassification. In addition, ML technology defends you in real-time against emerging dangers. Let's take a look at the three phases in more detail:
Payload Decoding
For ML to take place effectively, the data received over the network (payload) needs to be presented in a consistent form. The existing application protocols (which define the rules for communicating over networks) also need to be interpreted correctly. To achieve this, open-appsec examines all aspects of the HTTP request, from the headers to the URLs, JSON, and XML data. It extracts relevant data where necessary and decodes payloads to present it in a form that can be interpreted by the model. Payload is a vital step when it comes to Log4j attacks in which Base64 and escaping encodings are used to pass parameters into unsuspecting applications.
Attack Indicators
The next phase involves identifying indicators of attacks within HTTP requests. Attack indicators are patterns that are used to exploit various kinds of vulnerabilities. The parsed and normalized payload from phase 1 (payload decoding) is sent to an ML engine that evaluates it and identifies these indicators. Through a supervised learning process, open-appsec learns, and the model is trained on a large amount of payload data, each of which has been annotated with a confidence score indicating whether it is harmless or malicious. This score represents the likelihood that an attack follows a particular pattern. Naturally, adding the scores gained from identifying a number of patterns increases the confidence in the cumulative attack score. For instance, high scores from the command injection, probing, and remote code execution families in a Log4j attack indicate that the payloads are malicious. This phase is normally already sufficient, but to further reduce the possible occurrence of false positives, a final phase is performed.
Contextual Evaluation Engine
In the final phase, open-appsec uses a weighted function to assign a confidence score to the request using information from the specific environment, user, or URL. If this score is higher than a predefined threshold, then the request is not allowed. The following factors play an important role in the decision-making process:
Reputation: This refers to the score assigned to each request depending on the request originator's reputation. An originator's reputation is determined based on previous requests, and the assigned score is normalized and used to modify the confidence score.
Application awareness: This takes into consideration the dynamic nature of applications. Because specific applications can have features that are non-conventional and can be misinterpreted, ML is used to understand the applications' specific behavior. These features can include web page modification, script uploading, and special search query syntax.
User input format: The contextual engine considers the fact that some user inputs that are atypical are actually benign. Therefore it uses ML to identify these non-conventional input types so that legitimate uses are not misclassified in the detection process.
False detection factor: If the detection is not consistent, the evaluation engine adjusts the confidence score based on the reputation of the location where the detection was made.
Supervised learning factor: This is an optional factor in which administrators are allowed to partake in the detection process. They're asked to classify the payload, which speeds up the learning process.
Configuring Contextual ML for Accuracy
The contextual ML engine is more effective when it can identify the various sources of HTTP requests. For this reason, open-appsec lets you add configurations that help the model identify a request source in a particular web application or API. Once the model knows how to identify sources, you can also add a configuration that distinguishes trusted sources, helping the model quickly identify harmful requests.
Setting Trusted Sources
The third step in open-appsec's configuration process involves setting trusted sources. To do this, you need to first identify the web request's source. This source can be a source IP address, X-Forwarded-For, header key, JWT key, or cookie.
For some sources, additional user parameters must be added so that they can be uniquely identified:
Trusted sources can be configured in an asset by navigating to the *Source Identity** and Trusted Sources sections. Once you identify the source, you need to add the trusted IP addresses (for the source IP or XForwarded- For sources) or unique user identifiers (for header, JWT, or cookie sources) to a list to set the trusted sources, as shown in the previous image. By default, the number of users that you trust is set to three, but you can adjust that number as needed (reducing the number is not advised). If the value is set to four (as it is in the previous image), this means that such behavior will not be considered harmless until at least four of the specified sources produce similar traffic patterns. This keeps a supposedly reliable source from becoming a malicious source of truth.

Tracking Your Model's Learning Level
As the model learns from requests, it will progress to various maturity levels, including kindergarten, primary school, high school, graduate, master, and PhD:

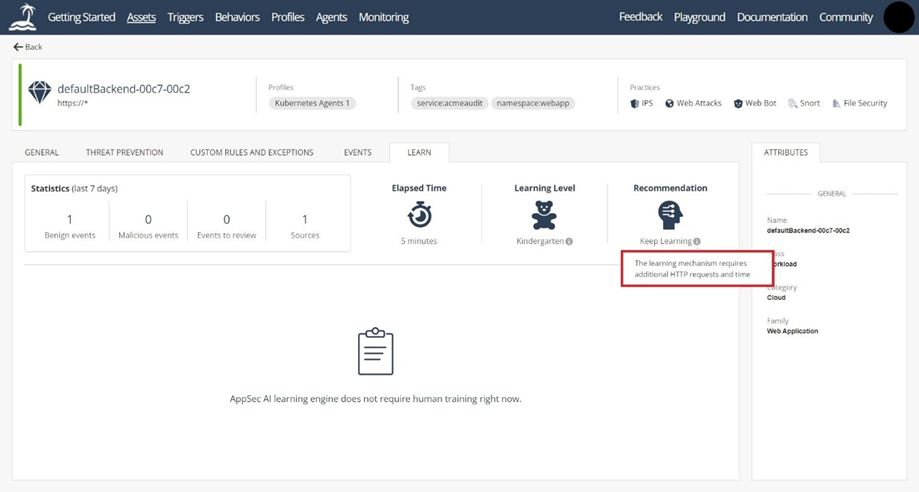
When the model progresses to the graduate level, you can change the asset mode from learn-detect, to prevent (for high confidence or above critical confidence events), which, as previously stated, can happen within two to three days if there is sufficient network traffic. If your asset has progressed to the prevent mode, the accuracy of your system is high. For your model to get to the master or PhD level, you have to configure trusted sources. At the PhD level, more learning is less likely to improve performance because model training at the PhD level is less effective since a high accuracy level has already been obtained. To track the learning level, navigate to the Assets tab and select the one you want to track. Then select the LEARN tab to view the learning statistics over the last week, the elapsed time, the learning level, and the recommendation at the said level:

You can hover over the Learning Level tooltip to find out your current and future learning level, with information about how to progress to the next level. There are all kinds of factors that contribute to progression, including the number of defined trusted sources, the amount of traffic inspected, and the time that has elapsed:

Similarly, if you want to know what the recommended action for the asset is, hover over Recommendation:

Possible recommendations include "keep learning," "review tuning suggestions," "prevent critical severity events," and "prevent high security & above events."
Moving to Prevent Mode
When your model has reached the graduate maturity level, open-appsec recommends that you change the mode to Prevent. To do this, you need to select the asset you wish to protect from the Assets tab. Then select the LEARN tab and view the Recommendation:
At the same time, you need to select the EVENTS tab and check the critical and high events from the last twenty-four to forty-eight hours. If necessary, right-click on an event and add exceptions for requests that may have been misclassified:

Then change the mode on the THREAT PREVENTION tab to Prevent:

With the Prevent mode active, you can either block critical events or High and above events. The LEARN tab will have recommendations for how you can move forward, but you can also choose to begin with Critical for a number of days, and if the performance is great, move to High and above. Finally, click the Enforce button on the top right to enforce the policy:

Implementing Tuning Suggestions
As the model learns, certain events will be highlighted for administrators to review. These are known as tuning suggestions and help the model learn faster. Though this is not compulsory, providing feedback helps the model reach a higher maturity level quickly. If you want to implement tuning suggestions, navigate to the Assets listing and select the asset of interest:


Then select the LEARN tab and review the tuning suggestions under the Tuning Suggestions and Tuning Decisions section. Next, click the Malicious or Benign button next to each tuning suggestion to provide feedback. This moves the suggestion to the Tuning Decision list. Finally, return to the Recommendation tooltip to find out what the next step should be to improve the learning process.
Conclusion
open-appsec is a fully automated web application and API security solution powered by ML. In this article, you learned how open-appsec works and how to implement it for your use case. The importance of security on the internet can never be overemphasized. With open-appsec, you can stay one step ahead of malicious agents that wish to disrupt your applications with new threats. open-appsec helps you achieve this using preemptive threat prevention, ML-based bot activity prevention, ML-based attack indicator detection, schema validation, and traditional signature-based protection (IPS with Snort support).
For even deeper dive into the technology refer to the white paper Preemptive Web Application Protection using Contextual Machine Learning.
